






Building Cross-Lingual End-to-End Product Search with Tensorflow
Background
Product search is one of the key components in an online retail store. Essentially, you need a system that matches a text query with a set of products in your store. A good product search can understand user’s query in any language, retrieve as many relevant products as possible, and finally present the result as a list, in which the preferred products should be at the top, and the irrelevant products should be at the bottom.
Unlike text retrieval (e.g. Google web search), products are structured data. A product is often described by a list of key-value pairs, a set of pictures and some free text. In the developers’ world, Apache Solr and Elasticsearch are known as de-facto solutions for full-text search, making them a top contender for building e-commerce product search.
At the core, Solr/Elasticsearch is a symbolic information retrieval (IR) system. Mapping query and document to a common string space is crucial to the search quality. This mapping process is an NLP pipeline implemented with Lucene Analyzer. In this post, I will reveal some drawbacks of such a symbolic-pipeline approach, and then present an end-to-end way to build a product search system from query logs using Tensorflow. This deep learning based system is less prone to spelling errors, leverages underlying semantics better, and scales out to multiple languages much easier.
Table of Content
- Recap Symbolic Approach for Product Search
- Pain points of Symbolic IR System
- Neural IR System
- Symbolic vs. Neural IR System
- Neural Network Architecture
- Training and Evaluation Scheme
- Qualitative Results
- Summary
Recap Symbolic Approach for Product Search
Let’s first do a short review of the classic approach. Typically, an information retrieval system can be divided into three tasks: indexing, parsing and matching. As an example, the next figure illustrates a simple product search system:
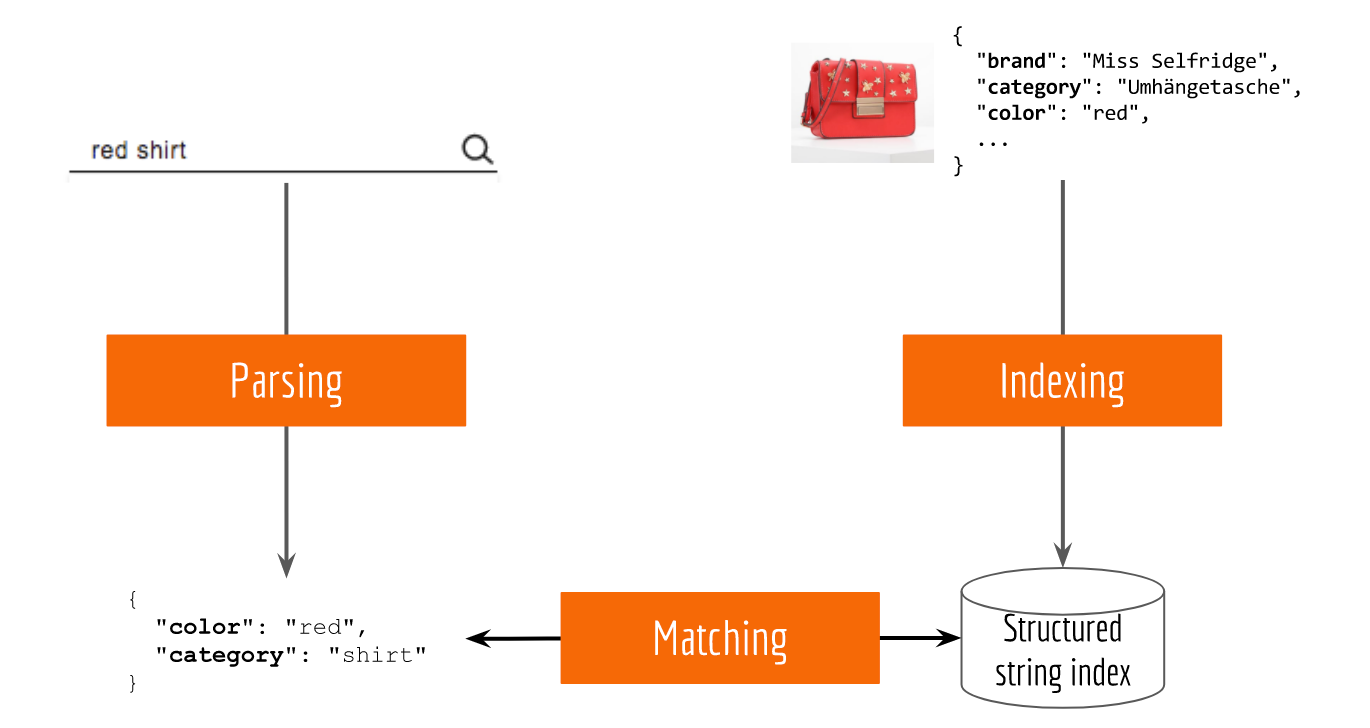
- indexing: storing products in a database with attributes as keys, e.g. brand, color, category;
- parsing: extracting attribute terms from the input query, e.g.
red shirt -> {"color": "red", "category": "shirt"}; - matching: filtering the product database by attributes.
If there is no attribute found in the query, then the system fallbacks to exact string matching, i.e. searching every possible occurrence in the database. Note that, parsing, and matching must be done for each incoming query, whereas indexing can be done less frequently depending on the stock update speed.
Many existing solutions such as Apache Solr and Elasticsearch follow this simple idea, except they employ more sophisticated algorithms (e.g. Lucene) for these three tasks. Thanks to these open-source projects many e-commerce businesses are able to build product search on their own and serve millions of requests from customers.
Symbolic IR System
Note, at the core, Solr/Elasticsearch is a symbolic IR system that relies on the effective string representation of the query and product. By parsing or indexing, the system knows which tokens in the query or product description are important. These tokens are the primitive building blocks for matching. Extracting important tokens from the original text is usually implemented as a NLP pipeline, consisting of tokenization, lemmatization, spelling correction, acronym/synonym replacement, named-entity recognition and query expansion.
Formally, given a query $q\in \mathcal{Q}$ and a product $p\in\mathcal{P}$, one can think the NLP pipeline as a predefined function that maps from $\mathcal{Q}$ or $\mathcal{P}$ to a common string space $\mathcal{S}$, i.e. $f: \mathcal{Q}\mapsto \mathcal{S}$ or $g: \mathcal{P}\mapsto \mathcal{S}$, respectively. For the matching task, we just need a metric $m: \mathcal{S} \times \mathcal{S} \mapsto [0, +\infty)$ and then evaluate $m\left(f(q),g(p)\right)$, as illustrated in the figure below.
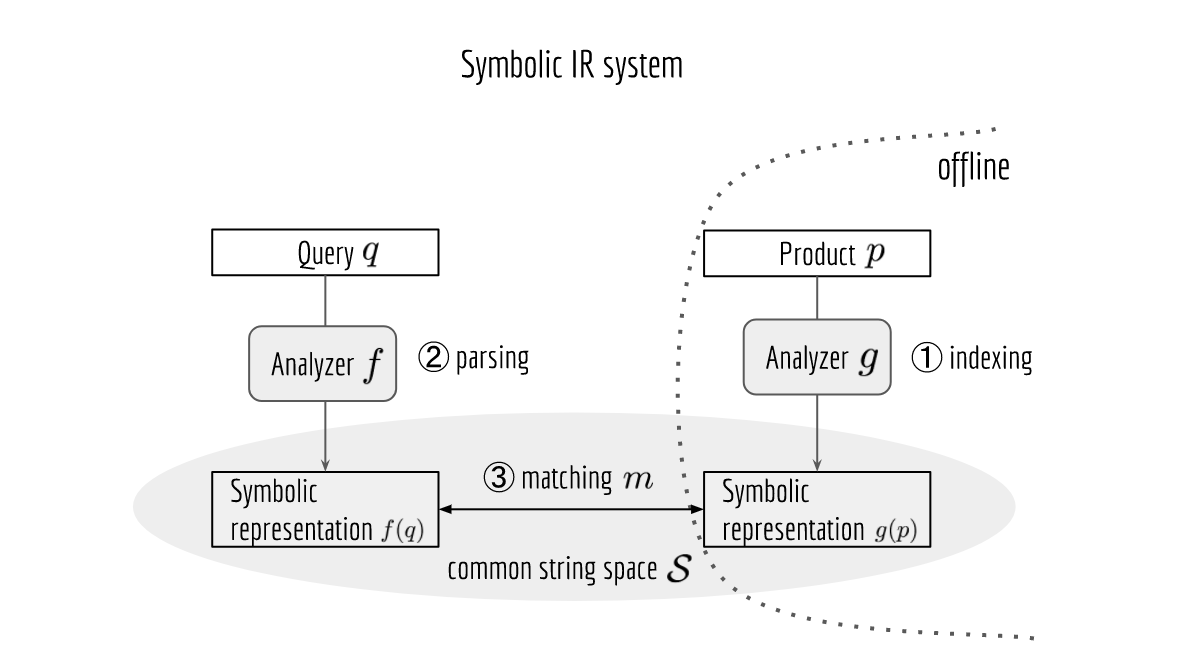
Pain points of Symbolic IR System
If you are a machine learning enthusiast who believes everything should be learned from data, you must have tons of questions about the last figure. To name a few:
- Why are $f$ and $g$ predefined? Why can’t we learn $f$ and $g$ from data?
- Why is $\mathcal{S}$ a string space? Why can’t it be a vector space?
- Why is $m$ a string/key matching function? Why can’t we use more well-defined math function, e.g. Euclidean distance, cosine function? Wait, why don’t we just learn $m$?
In fact, these questions reveal two pain points of a symbolic IR system.
1. NLP Pipeline is Fragile and doesn’t Scale Out to Multiple Languages
The NLP Pipeline in Solr/Elasticsearch is based on the Lucene Analyzer class. A simple analyzer such as StandardAnalyzer would just split the sequence by whitespace and remove some stopwords. Quite often you have to extend it by adding more and more functionalities, which eventually results in a pipeline as illustrated in the figure below.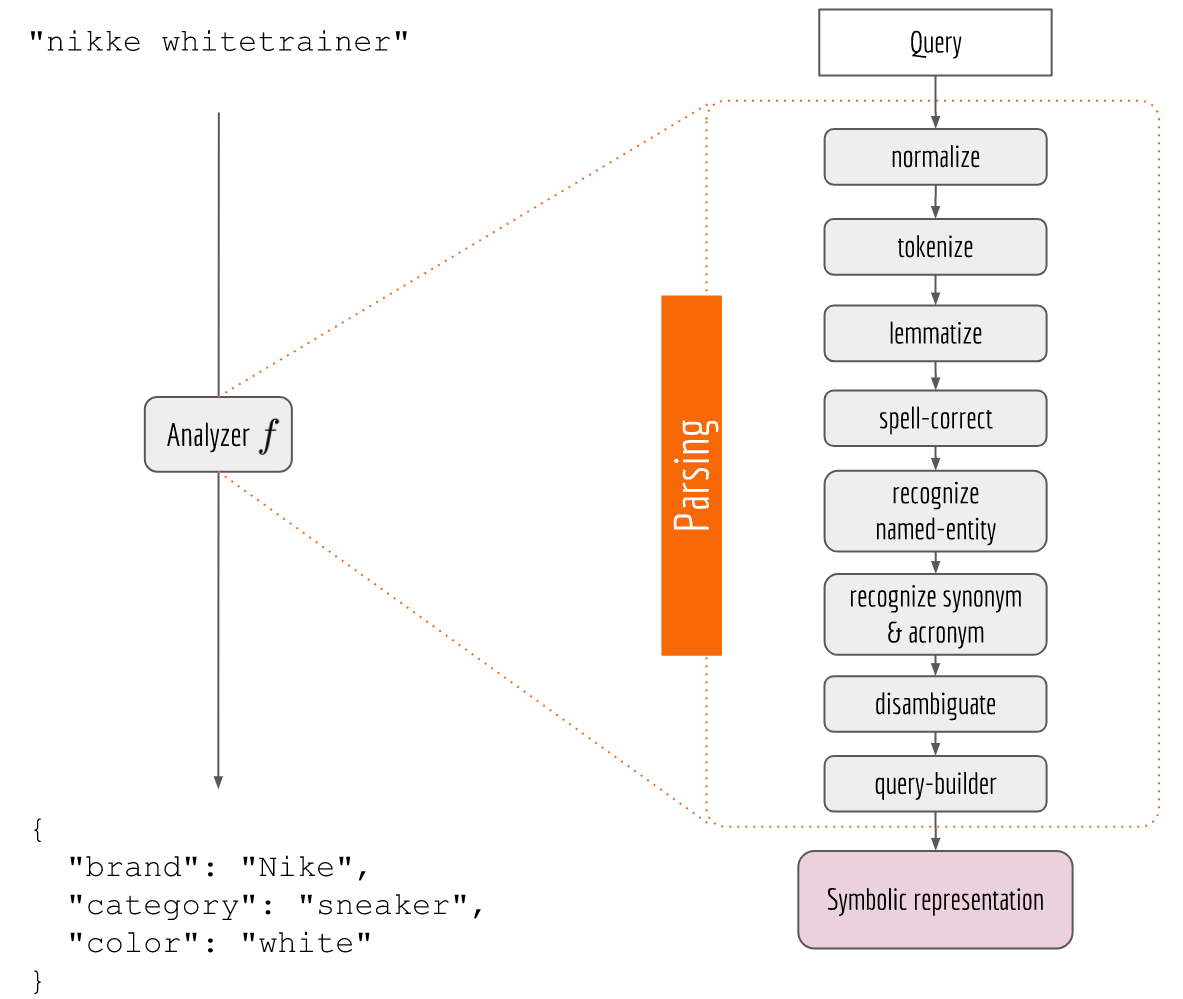
While it looks legit, my experience is that such NLP pipeline suffers from the following drawbacks:
- The system is fragile. As the output of every component is the input of the next, a defect in the upstream component can easily break down the whole system. For-example,canyourtoken izer split thiscorrectly⁇
- Dependencies between components can be complicated. A component can take from and output to multiple components, forming a directed acyclic graph. Consequently, you may have to introduce some asynchronous mechanisms to reduce the overall blocking time.
- It is not straightforward to improve the overall search quality. An improvement in one or two components does not necessarily improve the end-user search experience.
- The system doesn’t scale-out to multiple languages. To enable cross-lingual search, developers have to rewrite those language-dependent components in the pipeline for every language, which increases the maintenance cost.
2. Symbolic System does not Understand Semantics without Hard Coding
A good IR system should understand trainer is sneaker by using some semantic knowledge. No one likes hard coding this knowledge, especially you machine learning guys. Unfortunately, it is difficult for Solr/Elasticsearch to understand any acronym/synonym unless you implement SynonymFilter class, which is basically a rule-based filter. This severely restricts the generalizability and scalability of the system, as you need someone to maintain a hard-coded language-dependent lexicon. If one can represent query/product by a vector in a space learned from actual data, then synonyms and acronyms could be easily found in the neighborhood without hard coding.
Neural IR System
With aforementioned problems in mind, my motivation is twofold:
- eliminate the NLP pipeline to make the system more robust and scalable;
- find a space for query and product that can better represent underlying semantics.
The next figure illustrates a neural information retrieval framework, which looks pretty much the same as its symbolic counterpart, except that the NLP pipeline is replaced by a deep neural network and the matching job is done in a learned common space. Now $f$ serves as a query encoder, $g$ serves as a product encoder.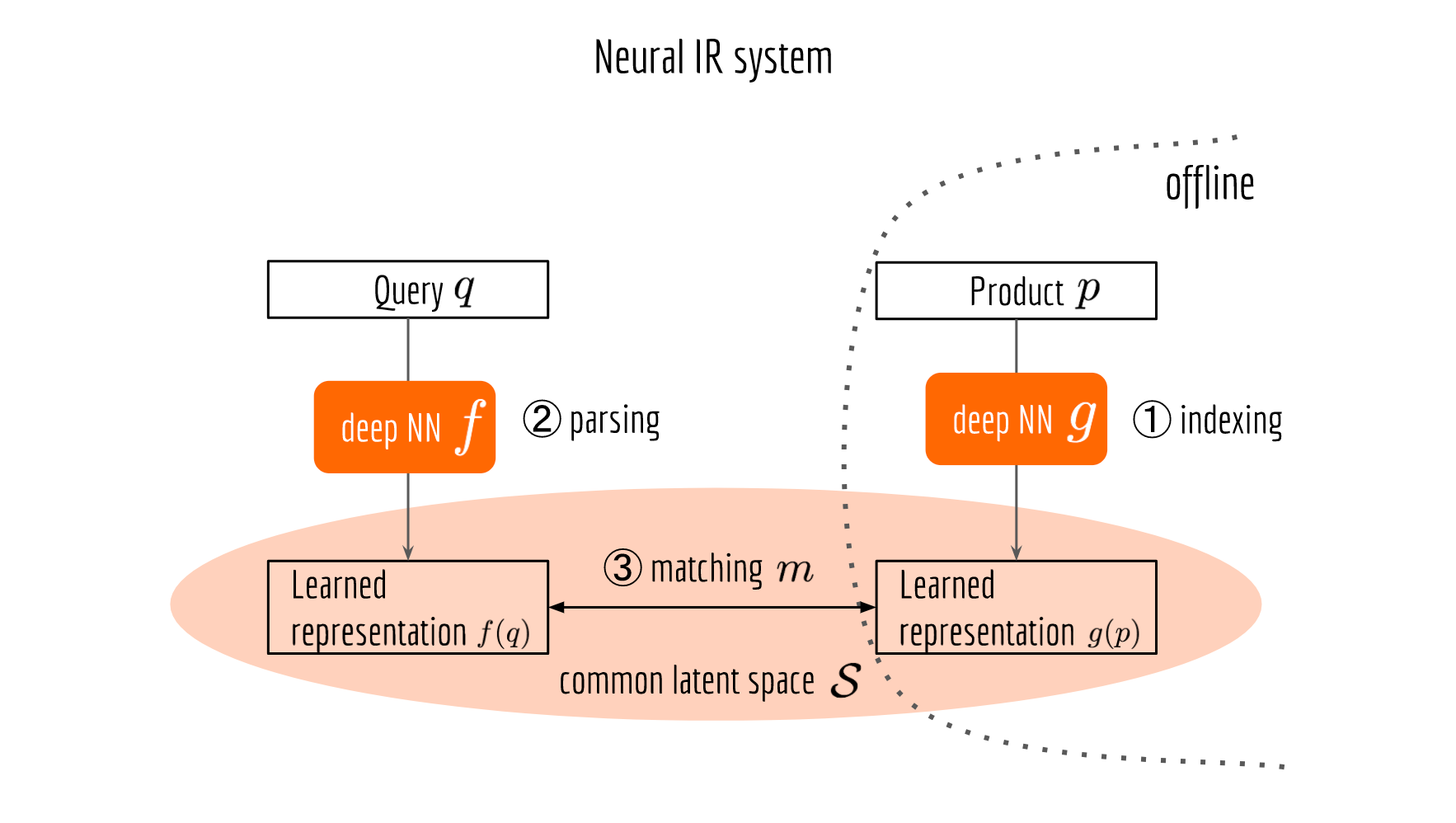
End-to-End Model Training
There are several ways to train a neural IR system. One of the most straightforward (but not necessarily the most effective) ways is end-to-end learning. Namely, your training data is a set of query-product pairs feeding on the top-right and top-left blocks in the last figure. All the other blocks such as $f$, $g$, $m$ and $\mathcal{S}$ are learned from data. Depending on the engineering requirements or resource limitations, one can also fix or pre-train some of the components.
Where Do Query-Product Pairs Come From?
To train a neural IR system in an end-to-end manner, your need some associations between query and product such as the query log. This log should contain what products a user interacted with (click, add to wishlist, purchase) after typing a query. Typically, you can fetch this information from the query/event log of your system. After some work on segmenting (by time/session), cleaning and aggregating, you can get pretty accurate associations. In fact, any user-generated text can be good association data. This includes comments, product reviews, and crowdsourcing annotations. The next figure shows an example of what German and British users clicked after searching for ananas and pineapple on Zalando, respectively.

Increasing the diversity of training data source is beneficial to a neural IR system, as you certainly want the system to generalize more and not to mimic the behavior of the symbolic counterpart. On the contrary, if your only data source is the query log of a symbolic IR system, then your neural IR system is inevitably biased. The performance of your final system highly depends on the ability of the symbolic system. For example, if your current symbolic system doesn’t correct spell mistakes and returns nothing when user types adidaas, then you won’t find any product associated with adidaas from the query log. As a consequence, your neural IR system is unlikely to learn the ability of spell checking.
In that sense, we are “bootstrapping” the symbolic IR system to build a neural IR system. Given enough training data, we hope that some previously hard-coded rules or manually coded functions can be picked up and generalized by deep neural networks.
What about Negative Query-Product Pairs?
At some point, you will probably need negative query-product pairs to train a neural IR system more effectively. In general, negative means that a product is irrelevant to the query. A straightforward way is just random sampling all products, hoping that no positive product gets accidentally sampled. It is easy to implement and actually not a bad idea in practice. More sophisticated solutions could be collecting those products that generate impressions on customers yet not receive any clicks as negative ones. This requires some collaborations between you, the frontend team and the logging team, making sure those no-click items are really uninterested to users, not due to screen resolution, lazy loading, etc.
If you are looking for a more formal and sounding solution, then Positive-Unlabeled Learning (PU learning) could be interesting to you. Instead of relying on the heuristics for identifying negative data, PU learning regards unlabeled data as negative data with smaller weights. “Positive-Unlabeled Learning with Non-Negative Risk Estimator” is a nice paper about the unbiased PU learning published in NIPS 2017.
Symbolic vs. Neural IR System
Before I dive into details, let’s take a short break. As you can see I spent quite some effort on explaining symbolic and neural IR systems. This is because the symbolic system is such a classic way to do IR, and developers get used to it. With the help of Apache Solr, Elasticsearch and Lucene, medium and small e-commerce businesses are able to build their own product search in a short time. It is the de-facto solution. On the other hand, Neural IR is a new concept emerging just recently. There are not so many off-the-shelf packages available. Plus, training a neural IR system requires quite some data. The next table summarizes the pros and cons of two systems.
| Symbolic IR system | Neural IR system | |
|---|---|---|
| Pros | Efficient in query-time; straightforward to implement; results are interpretable; many off-the-shelf packages. | Automatic; resilient to noise; scale-out easily; requires little domain knowledge. |
| Cons | Fragile; Hard-coded knowledge; high maintenance costs. | Less efficient in query-time; hard to add business rules; requires a lot of data. |
This is not a Team Symbol or Team Neural choice. Both systems have their own advantages and can complement each other pretty well. Therefore, a better solution would be combining these two systems in a way so that we can enjoy all advantages from both sides.
Neural Network Architecture
The next figure illustrates the architecture of the neural network. The proposed architecture is composed of multiple encoders, a metric layer, and a loss layer. First, input data is fed to the encoders which generate vector representations. Note that, product information is encoded by an image encoder and an attribute encoder. In the metric layer, we compute the similarity of a query vector with an image vector and an attribute vector, respectively. Finally, in the loss layer, we compute the difference of similarities between positive and negative pairs, which is used as the feedback to train encoders via backpropagation.
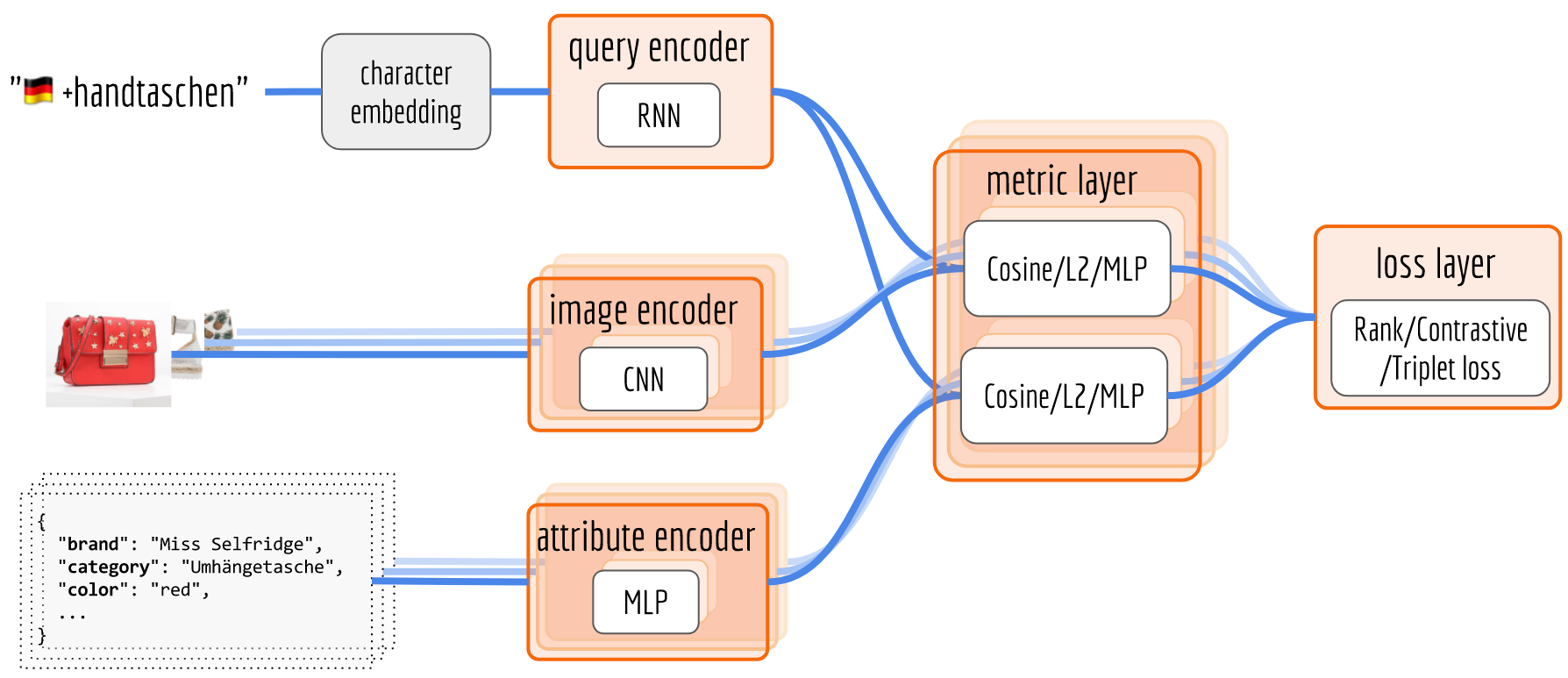
In the last figure, I labeled one possible model for each component, but the choices are quite open. For the sake of clarity, I will keep the model as simple as possible and briefly go through each component.
Query Encoder
Here we need a model that takes in a sequence and output a vector. Besides the content of a sequence, the vector representation should also encode language information and be resilient to misspellings. The character-RNN (e.g LSTM, GRU, SRU) model is a good choice. By feeding RNN character by character, the model becomes resilient to misspelling such as adding/deleting/replacing characters. The misspelled queries would result in a similar vector representation as the genuine one. Moreover, as European languages (e.g. German and English) share some Unicode characters, one can train queries from different languages in one RNN model. To distinguish the words with the same spelling but different meanings in two languages, such as German rot (color red) and English rot, one can prepend a special character to indicate the language of the sequence, e.g. 🇩🇪 rot and 🇬🇧 rot.
Using characters instead of words as model input means that your system is unlikely to meet an out-of-vocabulary word. Any input will be encoded into a vector representation. Consequently, the system has a good recall rate, as it will always return some result regardless the sanity of the input. Of course, the result could be meaningless. However, if a customer is kind and patient enough to click on one relevant product, the system could immediately pick up this signal from the query log as a positive association, retrain the model and provide better results in the next round. In that sense, we close the loop between feedback to users and learning from users.
Note that, a query can be compositional. It may contain multiple words and describe multiple attributes, such as nike sneaker (brand + category) and nike air max (brand + product name). Unfortunately, it is difficult for a plain character RNN to capture the high-order dependency and concept, as its resolution is limited to a single character. To solve this problem, I stack multiple dilated recurrent layers with hierarchical dilations to construct a Dilated Recurrent Neural Networks, which learns temporal dependencies of different scales at different layers. The next figure illustrates a three-layer DilatedRNN with dilation up to 4.
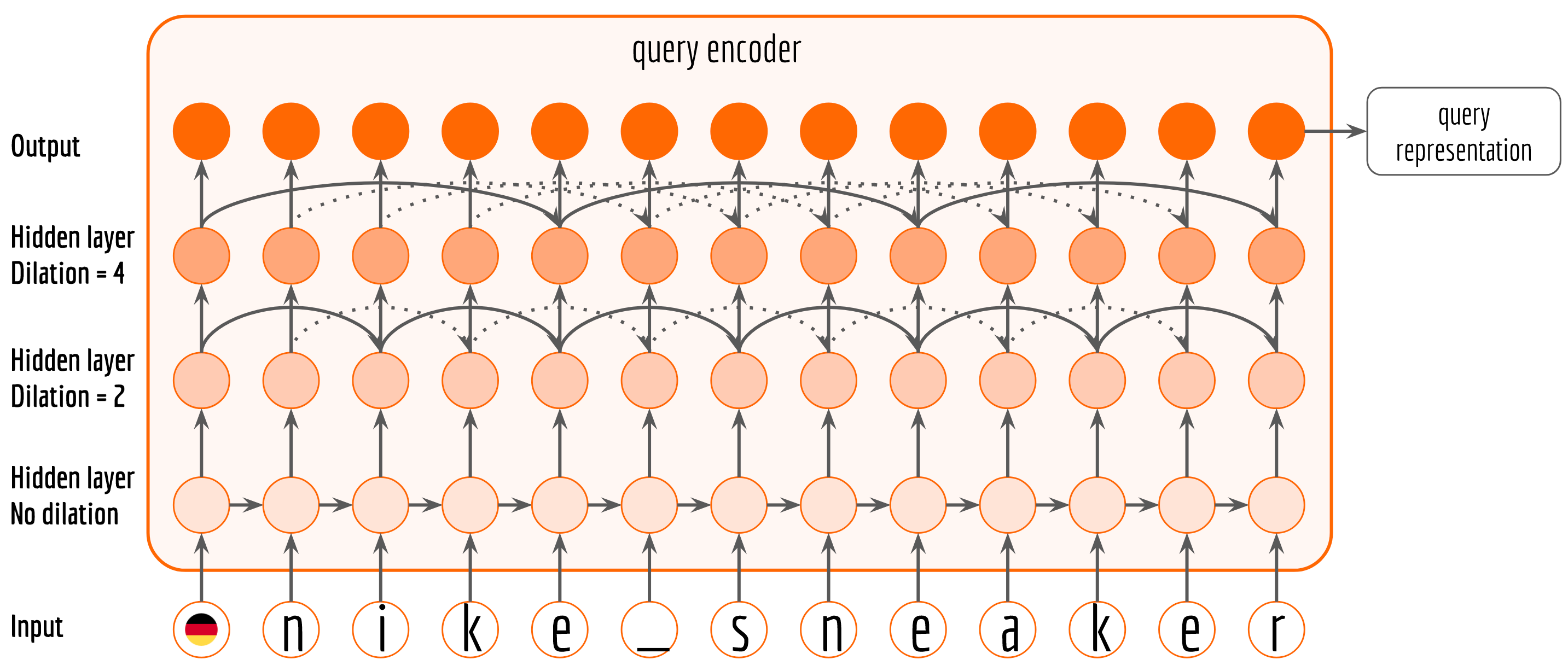
An implementation of dilated RNN using static_rnn API can be found here. The query representation is the last output from dilated RNN, which can be obtained via:
1 | num_hidden = 148 # 128+20 dims, this will become clear in the sequel |
To speed up training, one can also replace Tensorflow’s LSTMCell by recently proposed Simple Recurrent Unit (SRU). According to the paper, SRU is 5-10x faster than an optimized LSTM implementation. The code can be found here.
If you are interested in extending query encoder further, such as adding a more complicated high-order dependency or integrating side information in each recursion step, please read my blog post on Why I Use raw_rnn Instead of dynamic_rnn in Tensorflow and So Should You.
Image Encoder
The image encoder rests on purely visual information. The RGB image data of a product is fed into a multi-layer convolutional neural network based on the ResNet architecture, resulting in an image vector representation in 128-dimensions.
Attribute Encoder
The attributes of a product can be combined into a sparse one-hot encoded vector. It is then supplied to a four-layer, fully connected deep neural network with steadily diminishing layer size. Activation was rendered nonlinear by standard ReLUs, and drop-out is applied to address overfitting. The output yields attribute vector representation in 20 dimensions.
Some readers may question the necessarity of having image and attribute encoders at the same time. Isn’t an attribute encoder enough? If you think about search queries in the e-commerce context, especially in the fashion e-commerce I’m working in, queries can be loosely divided into two categories: “attribute” queries e.g.
nike red shoes, of which all words are already presented in the product database as attributes; and “visual” queries e.g. tshirt logo on back, typical berlin that express more visual or abstract intent from user, and those words never show up in the product database. The former can be trained with attribute encoder only, whereas the latter requires image encoder for effective training. Having both encoders allows some knowledge transfer between them during the training time, which improves the overall performance.Metric & Loss Layer
After a query-product pair goes through all three encoders, one can obtain a vector representation $q$ of the query, an image representation $u$ and an attribute representation $v$ of the product. It is now the time to squeeze them into a common latent space. In the metric layer, we need a similarity function $m$ which gives higher value to the positive pair than the negative pair, i.e. $m(q, u^+, v^+) > m(q, u^-, v^-)$. The absolute value of $m(q, u^+, v^+)$ does not bother us too much. We only care about the relative distances between positive and negative pairs. In fact, a larger difference is better for us, as a clearer separation between positive and negative pairs can enhance the generalization ability of the system. As a consequence, we need a loss function $\ell$ which is inversely proportional to the difference between $m(q, u^+, v^+)$ and $m(q, u^-, v^-)$. By splitting $q$ (148-dim) into $q^{\mathrm{img}}$ (128-dim) and $q^{\mathrm{attr}}$ (20-dim), we end up minimizing the following loss function:
$${\begin{aligned}&\sum_{\tiny\begin{array}{c} 0<i<N\\ 0<j<|q_{i}^{+}| \\ 0<k<|q_{i}^{-}|\end{array}}\lambda\ell\left(m(q^{\mathrm{img}}_i, u_{i,j}^{+}), m(q^{\mathrm{img}}_i, u_{i,k}^{-})\right) \\ &+ (1-\lambda)\ell\left(m(q^{\mathrm{attr}}_i, v_{i,j}^{+}), m(q^{\mathrm{attr}}_i, v_{i,k}^{-})\right),\end{aligned}}$$
where $N$ is the total number of queries. $|q_{i}^{+}|$ and $|q_{i}^{-}|$ are the number of positive and negative products associated with query $i$, respectively. Hyperparameter $\lambda$ trades off between image information and attribute information. For functions $\ell$ and $g$, the options are:
- Loss function $\ell$: logistic, exponential, hinge loss, etc.
- Metric function $m$: cosine similarity, euclidean distance (i.e. $\ell_2$-norm), MLP, etc.
To understand how it ends up with the above loss function, I strongly recommend you read my other blog post on Optimizing Contrastive/Rank/Triplet Loss in Tensorflow for Neural Information Retrieval. It also explains the metric and loss layer implementation in details.
Inference
For a neural IR system, doing inference means serving search requests from users. Since products are updated regularly (say once a day), we can pre-compute the image representation and attribute representation for all products and store them. During the inference time, we first represent user input as a vector using query encoder; then iterate over all available products and compute the metric between the query vector and each of them; finally, sort the results. Depending on the stock size, the metric computation part could take a while. Fortunately, this process can be easily parallelized.
Training and Evaluation Scheme
The query-product dataset is partitioned into four sets as illustrated in the next figure.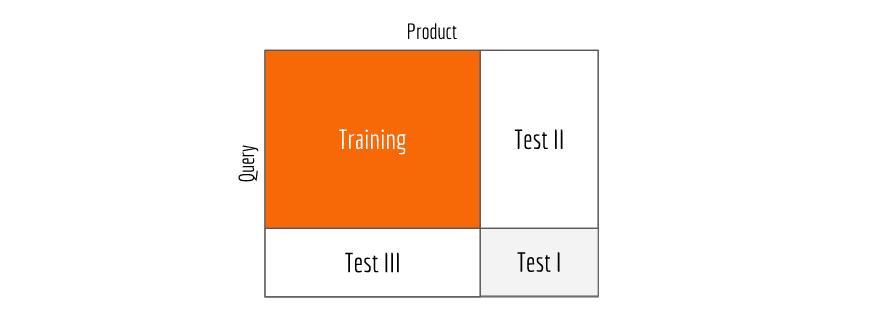
Data in the orange block is used to train the model, and the evaluation is performed on Test I set. In this way, the model can’t observe any query or product used for training during the test time. For evaluation, we feed the query to the network and return a sorted list of test products. Then we check how groundtruth products are ranked in the results. Some widely-used measurements include: mean average precision (MAP), mean reciprocal rank (MRR), precision@1, precision@1%, negative discounted cumulative gain (NDCG) etc. A comprehensive explanation of these metrics can be found in this slides. With Estimator and Data API in Tensorflow 1.4, you can easily define the training and evaluation procedure as follows:
1 | model = tf.estimator.Estimator(model_fn=neural_ir, params=params) |
Test II or Test III sets can be also used for evaluation to check how the model generalizes on unseen products or unseen queries, respectively.
Qualitative Results
Here I will not present any quantitative result. After all, it is a blog, not an academic paper and the goal is mainly to introduce this new idea of neural IR system. So let’s look at some results that are easy to your eyes. This actually poses a good question: how can you tell an IR system is (not) working by visual inspection only?
Personally, I call an IR system “working” if it meets these two basic conditions:
- it understands singleton query described by a basic concept, e.g. brand, color, category;
- it understands compositional query described by multiple concepts, e.g. brand + color, brand + color + category + product name.
If it fails to meet these two conditions, then I don’t bother to check fancy features such as spell-checking and cross-lingual. Enough said, here are some search results.
| Query & Top-20 Results |
|---|
🇩🇪 nike |
 |
🇩🇪 schwarz (black) |
 |
🇩🇪 nike schwarz |
 |
🇩🇪 nike schwarz shirts |
 |
🇩🇪 nike schwarz shirts langarm (long-sleeved) |
 |
🇬🇧 addidsa (misspelled brand) |
 |
🇬🇧 addidsa trosers (misspelled brand and category) |
 |
🇬🇧 addidsa trosers blue shorrt (misspelled brand and category and property) |
 |
🇬🇧 striped shirts woman |
 |
🇬🇧 striped shirts man |
 |
🇩🇪 kleider (dress) |
 |
🇩🇪 🇬🇧 kleider flowers (mix-language) |
 |
🇩🇪 🇬🇧 kleid ofshoulder (mix-language & misspelled off-shoulder) |
 |
Here I demonstrated (cherry-picked) some results for different types of query. It seems that the system goes in the right direction. It is also exciting to see that the neural IR system is able to correctly interpret named-entity, spelling errors and multilinguality without any NLP pipeline or hard-coded rule. However, one can also notice that some top ranked products are not relevant to the query, which leaves quite some room for improvement.
Speed-wise, the inference time is about two seconds per query on a quad-core CPU for 300,000 products. One can further improve the efficiency by using model compression techniques, approximate nearest neighbour search, e.g. Faiss (Facebook), Nmslib (Leonid Boytsov), and Annoy (Spotify).
Summary
If you are a search developer who is building a symbolic IR system with Solr/Elasticsearch/Lucene, this post should make you aware of the drawbacks of such a system. It should also answer your What? Why? and How? questions regarding a neural IR system. Comparing to the symbolic counterpart, the new system is more resilient to the input noise and requires little domain knowledge about the products and languages. Nonetheless, one should not take it as a Team Symbol or Team Neural kind of choice. Both systems have their own advantages and can complement each other pretty well. A better solution would be combining these two systems in a way that we can enjoy all advantages from both sides.
Some implementation details and tricks are omitted here but can be found in my other posts. I strongly recommend readers to continue with the following posts:
- Optimizing Contrastive/Rank/Triplet Loss in Tensorflow for Neural Information Retrieval
- Why I Use raw_rnn Instead of dynamic_rnn in Tensorflow and So Should You
Last but not least, the open-source project MatchZoo contains many state-of-the-art neural IR algorithms. In addition to product search, you may find its application in conversational chatbot, question-answer system.